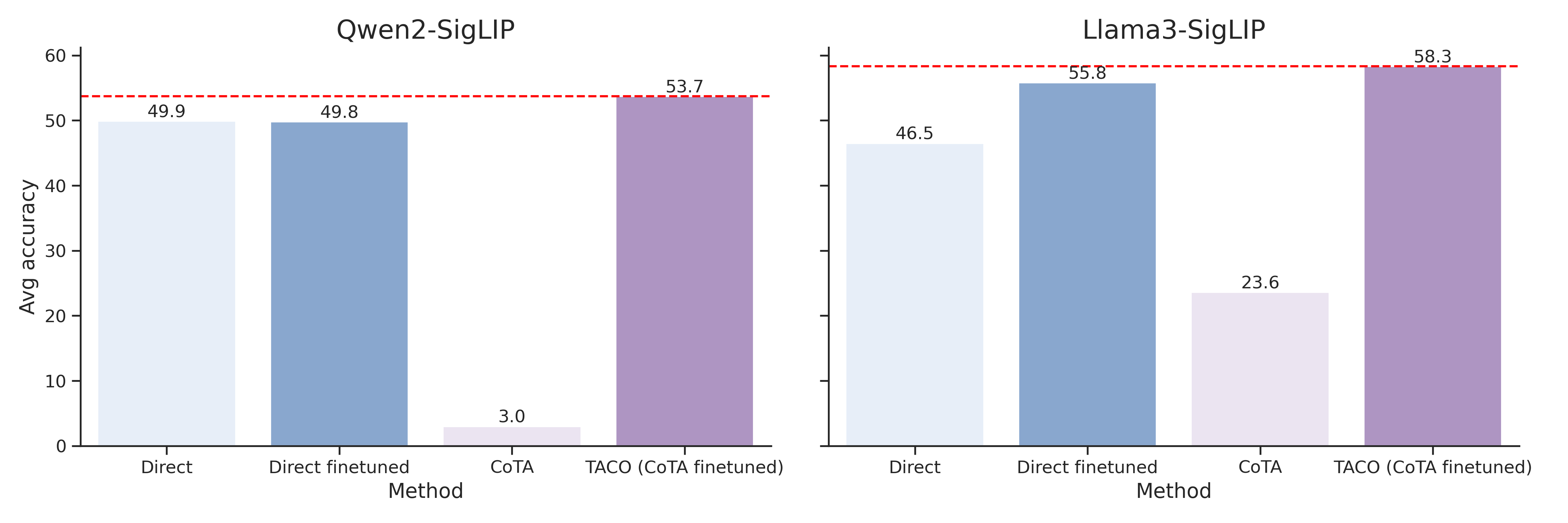
Figure 2. We illustrate our model-based data generation (top) and programmatic generation (bottom) pipelines.
In model-based generation, we take existing image and QA pairs as inputs and prompt GPT-4o to Generate either a chain-of-thought-and-action (CoTA) or chain-of-thought (CoT)
without actions to answer the questions. Then, we Verify that the chains lead to correct
final answers and Parse successfully; if not, we convert them into the direct answer (Direct)
format with groundtruth answers.
In programmatic generation, we first Annotate images with
human labelers or models, and then use the dense annotations to fill in manually written templates and
Generate QA and the corresponding CoTA with Python programs.
CoTA Data Distribution
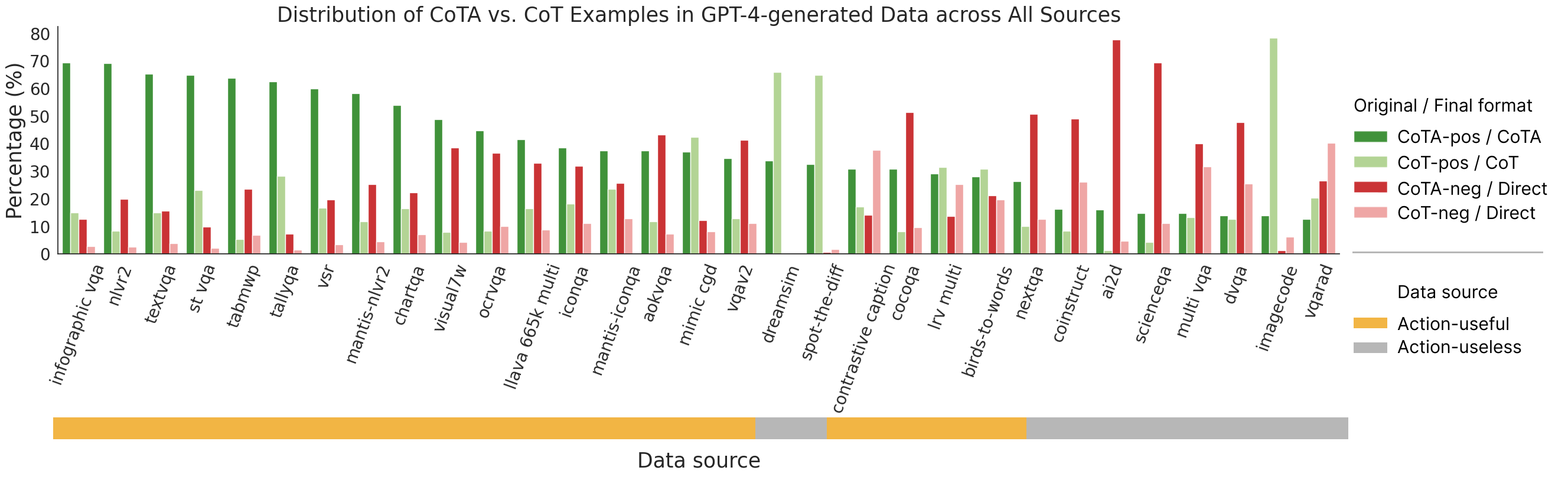
Figure 3. We visualize the frequency of data formats (i.e. CoTA-pos/neg, and CoT-pos/neg) in the original
GPT-4-generated data and in our final training data (i.e. CoTA, CoT, or Direct) in each dataset
across all data sources. We also highlight the Action-useless (i.e. datasets where % of CoT-pos - CoTA-pos >
10 or % of CoTA-neg - CoTA-pos > 10) vs. Action-useful datasets.